ladyLein startpagina

0. R install & library
1. R start
2. Vectoren
(een rij waarden)
3. Matrixen
(tabellen)
4. Statistieken
(min, max, gemiddelde, standaard defiatie)
5. Factoren
(-categorieën/typen)
6. Data frames
(wat is een dataframe,
inlezen txt en csv bestanden)
7. Correlatie in de grafiek
8. Plot
9. GGplot2
(lijn, staaf, taart)
10. Functies
(o.a.if else, for, while, string, datum)
11. SQL / dplyr
(gegevens ophalen uit tabellen)
12. WAR meetkastjes en KNMI
(data ophalen en in grafiek zetten)
13. Qgis
gegevens op de kaart zetten
|
SQL met R / dplyr zoals het hoort in R
Doe leuk met data
Je kan SQL doen met de library sqldf en je kan hetzelfde doen met de library dpryr.
Met de library dpryr kan je meer.
Echte R-programmeurs gruwelen van SQL in R.
Ken je geen SQL, doe dan dplyr.
Maar als je SQL gewend bent dan is de sqldf library de snelste manier om met tabellen te werken.
Verschill in het voordeel van dplyr:
Aan het eind van de pagina bij joins kan sqldf alleen de inner join en dplyr kan alle joins.
klik hier voor cheatsheet van dplyr: dplyr cheatsheet.pdf
Je kan data uit één of meerdere tabellen halen.
Twee voorbeeld tabellen.
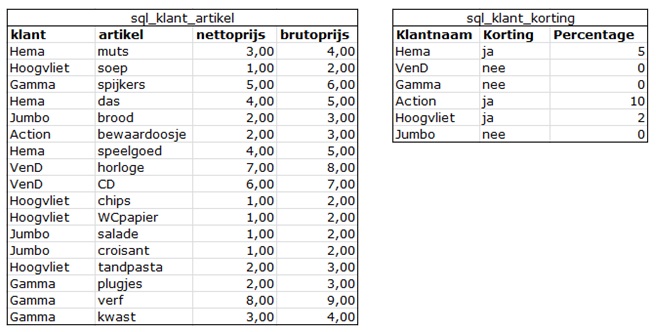
De tabellen inlezen in R
Tone<- read.csv2("C://R/VB/sql_klant_artikel.csv", sep = ";", header = T)
Ttwo<- read.csv2("C://R/VB/sql_klant_korting.csv", sep = ";", header = T)
SQL
De code om gegevens mee op te halen heet bij SQL een sql statement.
In R is dat een string en moet dus tussen " ".
Om het sql statement uit te voeren gebruikt R de functie sqldf()
En die kan je in een variabele zetten.
Resultaat <- sqldf("select * from Tone")
dplyr
Het resultaat van dplyr code kan je ook in een variabele zetten.
Deze code is geen string dus heb je geen ""nodig.
Resultaat <- select(Tone, klant, artikel, nettoprijs, brutoprijs)
Gegevens uit één tabel halen
SQL
velden ophalen:
sqldf("select klant, artikel, nettoprijs, brutoprijs from Tone")
Een kolom heet in sql een veld.
dplyr
kolommen ophalen:
select(Tone, klant, artikel, nettoprijs, brutoprijs)
Alle velden
SQL
sqldf("Select * from Tone")
Antwoord is de hele tabel. * staat voor alle kolommen
dplyr
select(Tone, klant, artikel, nettoprijs, brutoprijs)
|

|
Velden naar keuze
SQL
sqldf("Select klant, artikel from Tone")
Antwoord is twee van de vier kolommen
dplyr
select(Tone, klant, artikel)
of alle kolommen behalve 1
select(Tone, -nettoprijs)
of een aantal kolommen op rij
select(Tone, artikel:brutoprijs)
|

|
Velden samenvoegen
met sql kan dat niet in R
dplyr
tabelnaam$nieuwveldnaam<-paste(tabelnaam$veld, "-", Tabelnaam$veld)
"-" mag je ook weglaten maar dan zitten de velden strak tegen elkaar.
|
|
Uitbreiden van zoek criteria
SQL
SQL is één zin die steeds langer kan worden.
dplyr
In dplyr worden stukjes code aan elkaar gekoppeld met %>%
|
|
Aan bepaalde waarden voldoen: where / filter
== is precies, = is soms ongeveer, dus altijd == gebruiken
SQL
sqldf("Select klant, artikel from Tone
where klant == 'Hoogvliet' ")
Hoogvliet is een string dus tussen ' '
(en niet " " want die gebruik je al)
Antwoord is alle rijen waar de klant Hoogvliet is
dplyr
filter(Tone, klant == "Hoogvliet")
Alles aan elkaar gebruik je %>%
Omdat je met de tabel begint,
hoef je die bij de volgende stukjes code niet meer te noemen.
Tone %>% select(klant, artikel)
%>% filter(klant == "Hoogvliet")
Antwoord is alle rijen waar de klant Hoogvliet is
|

|
SQL
sqldf("select klant, artikel from Tone where brutoprijs > 7")
Antwoord de twee rijen met de duurste artikelen
dplyr
Bij dplyr moet je eerst filteren op brutoprijs want dan zit de kolom er nog in, en dan de kolommen selecteren. Of beide kolommen selecteren.
Tone %>% filter(brutoprijs > 7)
%>% select(klant, artikel)
Antwoord de twee rijen met de duurste artikelen
|

|
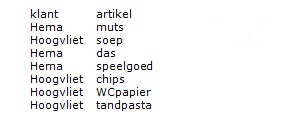
Waarde lijkt op: like
SQL
sqldf("Select klant, artikel from Tone where klant like 'H%'")
Antwoord alle rijen van Hoogvliet en Hema
dplyr
Tone %>% select(klant, artikel)
%>% filter(klant %like% "H")
Antwoord alle rijen van Hoogvliet en Hema
|
|
Waarde tussen twee waarden in: between
SQL
sqldf("select klant, artikel, brutoprijs from Tone
where brutoprijs between 2 and 5")
dplyr
Tone %>% select(klant, artikel, brutoprijs)
%>% filter(between(brutoprijs,2,5))
|

|
Meerdere where/filter: and, or, not
AND
SQL
sqldf("select klant, artikel from Tone
where klant like 'H%' and brutoprijs < 3")
dplyr
Tone %>% filter(klant %like% "H" & brutoprijs < 3)
%>% select(klant, artikel)
|

|
OR
SQL
sqldf("select klant, artikel, brutoprijs from Tone
where brutoprijs > 6 or artikel == 'speelgoed'")
dplyr
Tone %>% select(klant, artikel, brutoprijs)
%>% filter(brutoprijs > 6 | artikel == "speelgoed")
|

|
NOT
SQL
sqldf("select klant, artikel, brutoprijs from Tone
where NOT klant == 'VenD'")
dplyr
Tone %>% select(klant, artikel, brutoprijs)
%>% filter(klant != "VenD")
|
Alle klanten behalve VenD
|
Ongelijk aan !=
SQL
sqldf("select klant, artikel, brutoprijs from Tone
where klant == 'Hema' AND artikel !='speelgoed'")
dplyr
Tone %>% select(klant, artikel, brutoprijs)
%>% filter(klant == "Hema" & artikel !="speelgoed")
|

|
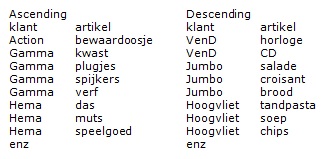
Op volgorde zetten: order by / arrange
Oplopend van A-Z = Asc van ascending en kan je weglaten, dat is de standaard
Aflopend van Z-A = Desc van descending en kan je niet weglaten.
Eerst wordt er op de eerste kolom op volgorde gezet, dan op de tweede, enz.
dus bijvoorbeeld: Ax, Ay, Az, Bk, Bl, Bm
SQL
sqldf("select klant, artikel from Tone order by klant, artikel")
sqldf("select klant, artikel from Tone order by klant, artikel desc")
dplyr
Tone %>% select(klant, artikel) %>% arrange(klant, artikel)
Tone %>% select(klant, artikel) %>% arrange(desc(klant), desc(artikel))
|
|
Aantal, optellen, min, max, gemiddeld met group by
Group by gebruik je om groepen te maken waar je weer wat mee kan doen.
Bijvoorbeeld het aantal rijen in elke de groep tellen.
Het resultaat wordt een nieuwe kolom die je een naam geeft, bv aantal
SQL
sqldf("select klant, count(klant) as aantal from Tone
group by klant")
Overige mogelijkheden zijn:
sum(veldnaam) als opgeteld
min(veldnaam) as minimum
max(veldnaam) as maximun
avg(veldnaam) as gemiddeld
dplyr
Tone %>% select(klant) %>% arrange(klant)
%>% group_by(klant) %>% summarise(aantal = n())
de functie n (aantal tellen) heeft altijd lege ()
Overige mogelijkheden zijn:
summarise(opgeteld=sum(brutoprijs))
summarise(gemiddeld=mean(brutoprijs))
summarise(ander_gemiddeld=median(brutoprijs))
summarise(minimum=min(brutoprijs))
summarise(maximum=max(brutoprijs))
|

|
Rekenen met velden
Als je meerder velden hebt met nummerieke waarden dan kan je daarmee rekenen.
SQL
sqldf("select klant, artikel, brutoprijs, nettoprijs,
brutoprijs-nettoprijs as verschil from Tone")
dplyr
Tone %>% select(klant, artikel, brutoprijs,nettoprijs)
%>% mutate(verschil=brutoprijs-nettoprijs)
|

|
SQL
sqldf("select klant, artikel, brutoprijs,
brutoprijs+1 as prijsverhoging from Tone")
dplyr
Tone %>% select(klant, artikel, brutoprijs)
%>% mutate(prijsverhoging=brutoprijs+1)
|

|
SQL
sqldf("select klant, artikel, brutoprijs,
brutoprijs/100*21 as BTW from Tone")
dplyr
Tone %>% select(klant, artikel, brutoprijs)
%>% mutate(BTW=(brutoprijs/100)*21)
|

|
Gegevens uit meerdere tabellen halen
Soorten joins
Er zijn meerdere soorten join.
In sqldf werkt alleen de inner join.
Ook de left join hoort te werken maar die levert hetzelfde op als de inner join.
De right join en outer join kent sqldf niet.
Daarvoor moet je dplyr gebruiken.
De inner join haalt alle gegevens op waarbij in alle tabellen rijen voor zijn.
De left join haalt alle rijen op uit de linker tabel en bijhorende rijen uit de andere tabel als die er zijn.
De right join haalt alle rijen op uit de rechter tabel en bijhorende rijen uit de andere tabel als die er zijn.
De outer join haalt alle rijen op.
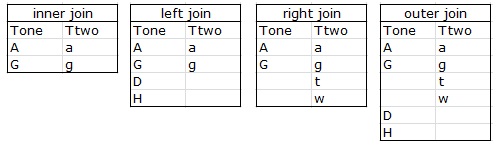
De tabellen worden gekoppeld door een veld of kolom.
Bijvoorbeeld de klantnaam, of een ID.
In dplyr moet deze koppel-kolom in beide tabellen dezelfde naam hebben.
In SQL hoeft dat niet.
Inner join
SQL
sqldf("select Tone.klant, Tone.artikel, Tone.brutoprijs,
Ttwo.Korting, Ttwo.Percentage from Tone inner join Ttwo
where Tone.klant = Ttwo.Klantnaam")
dplyr
Eerst gelijke kolomnamen in beide tabellen
Dan tabellen samenvoegen
Dan velden selecteren, sorteren, group by en filter enz
colnames(Ttwo) <- c("klant", "Korting", "Percentage")
Result1<-inner_join(Tone, Ttwo, by = "klant")
Result1 %>% select(klant, artikel, brutoprijs, Korting, Percentage)
|

|
Overige joins
left, righ, outer of full
Omdat bij de voorbeeld-tabellen alles matcht,
zie je geen verschil.
Daarvoor moet je andere tabellen nemen.
SQL
Je kan de kolommen selecteren die je wilt
Result2<-sqldf("select Tone.klant, Tone.artikel,
Ttwo.Korting from Tone left join Ttwo
where Tone.klant = Ttwo.Klantnaam")
Result3<-sqldf("select Tone.klant, Tone.artikel
Ttwo.Korting from Tone right join Ttwo
where Tone.klant = Ttwo.Klantnaam")
Result4<-sqldf("select Tone.klant, Tone.artikel,
Ttwo.Korting from Tone outer join Ttwo
where Tone.klant = Ttwo.Klantnaam")
dplyr
Result2<-left_join(Tone, Ttwo, by = "klant")
Result2 %>% select(klant, artikel, brutoprijs, Korting, Percentage)
Result3<-right_join(Tone, Ttwo, by = "klant")
Result3 %>% select(klant, artikel, brutoprijs, Korting, Percentage)
Result4<-full_join(Tone, Ttwo, by = "klant")
Result4 %>% select(klant, artikel, brutoprijs, Korting, Percentage)
|
|
inner join die aan een waarde voldoet
SQL
sqldf("select Tone.klant, Tone.artikel, Tone.brutoprijs,
Ttwo.Korting from Tone inner join Ttwo
where Tone.klant = Ttwo.Klantnaam and korting = 'nee'")
dplyr
colnames(Ttwo) <- c("klant", "Korting", "Percentage")
Result1<-inner_join(Tone, Ttwo, by = "klant")
Result1 %>% select(klant, artikel, brutoprijs, Korting)
%>% filter(Korting=="nee")
|

|
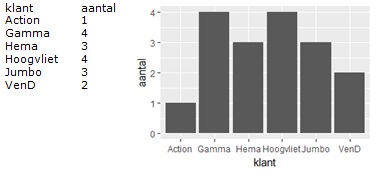
Grafiek van sql
SQL/dplyr
Je kan het resultaat van een sql of dplyr statement
in een variabele zetten en die plotten.
VoorGrafiek<- sql of dplyr statement
ggplot(data=VoorGrafiek, aes(x=klant, y=aantal)) +
geom_bar(stat="identity")
|
|
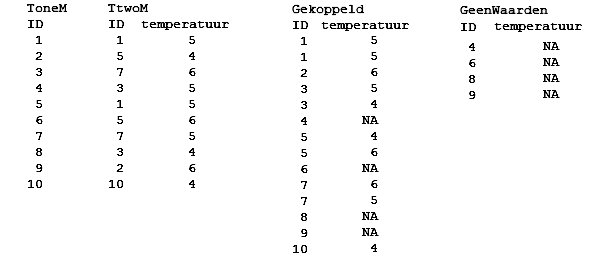
Welke rijen hebben geen match
Met is.na(kolomnaam) kan je lege waarden vinden.
Met !is.na(kolomnaam) vind je niet lege waarden.
Bijvoorbeeld welke meetkastjes staat uit,
leveren geen meetgegevens meer.
ToneM heeft de ID's van de meetkastjes.
TtwoM heeft de meetgegevens.
De tabellen inlezen in R
ToneM<- read.csv2("C://R/VB/ToneM.csv",
sep = ";", header = T)
TtwoM<- read.csv2("C://R/VB/TtwoM.csv",
sep = ";", header = T)
SQL
GeenWaarden<-sqldf("select ToneM.ID, TtwoM.ID, TtwoM.temp from ToneM
left join TtwoM where ToneM.ID == TtwoM.ID and TtwoM.temp IS NULL")
Resultaat is leeg omdat hij reageert als inner join
dplyr
Check of de kolomnamen hetzelfde zijn
tabellen koppelen
TabellenSamen<-left_join(ToneM, TtwoM, by = "ID")
GeenWaarden<-TabellenSamen
%>% select(ID, temperatuur)
%>% group_by(ID) %>% filter(is.na(temperatuur))
|
|
Je kan GeenWaarden bewaren in een bestand.
Voorbeeld bestandsnaam met datum van vandaag.
Dag van vandaag
today<-format(Sys.Date(), format="%Y%m%d")
Bestandnaam maken inclusief pad
bestandsnaam<-paste("C://R/MJS/", today, "LijstZonderWaarden.txt", sep = "", collapse = "")
Dat wordt dan: "C://R/MJS/20190303LijstZonderWaarden.txt"
Naar bestand schrijven
write.table(GeenWaarden, bestandsnaam, sep="\t")
Terug naar top
|